EfficientNet: Rethinking model scaling for convolutional neural networks 链接到标题
* Authors: [[Mingxing Tan]], [[Quoc V. Le]]
初读印象 链接到标题
探索了模型的深度、宽度以及输入分辨率对模型性能和速度的影响,基于此提出了 EfficientNet 这种高效的模型结构
文章骨架 链接到标题
%%创新点到底是什么?%% novelty:: 探索了模型的深度、宽度和输入分辨率对模型速度和精度的影响,并科学地将三折结合得到最高效的结构。
%%有什么意义?%% significance:: 提出了增加或压缩模型时同时保证速度和精度的通用模式
%%有什么潜力?%% potential:: 基于 EffientNet 的 EfficientNet-B7 在 ImageNet 上达到了 84.3% 的新 SOTA, 同时相比之前最好的模型小 8.4倍, 快6.1倍

我们知道在更大的算力下,可以通过增加模型的深度、宽度或者增大输入的分辨率来达到提升模型性能的目标, 但是怎样科学的将三者结合最高效得提点一直缺乏研究。
本文系统地分析了三者和模型性能的关系,提出了一种放大模型的范式实现高效提点, 在 ResNet、 MobileNet 以及 NAS 搜索出来的 EfficientNet 下验证了它的效果, 基于 EffientNet 的 EfficientNet-B7 在 ImageNet 上达到了 84.3% 的新 SOTA, 同时相比之前最好的模型小 8.4倍, 快6.1倍。
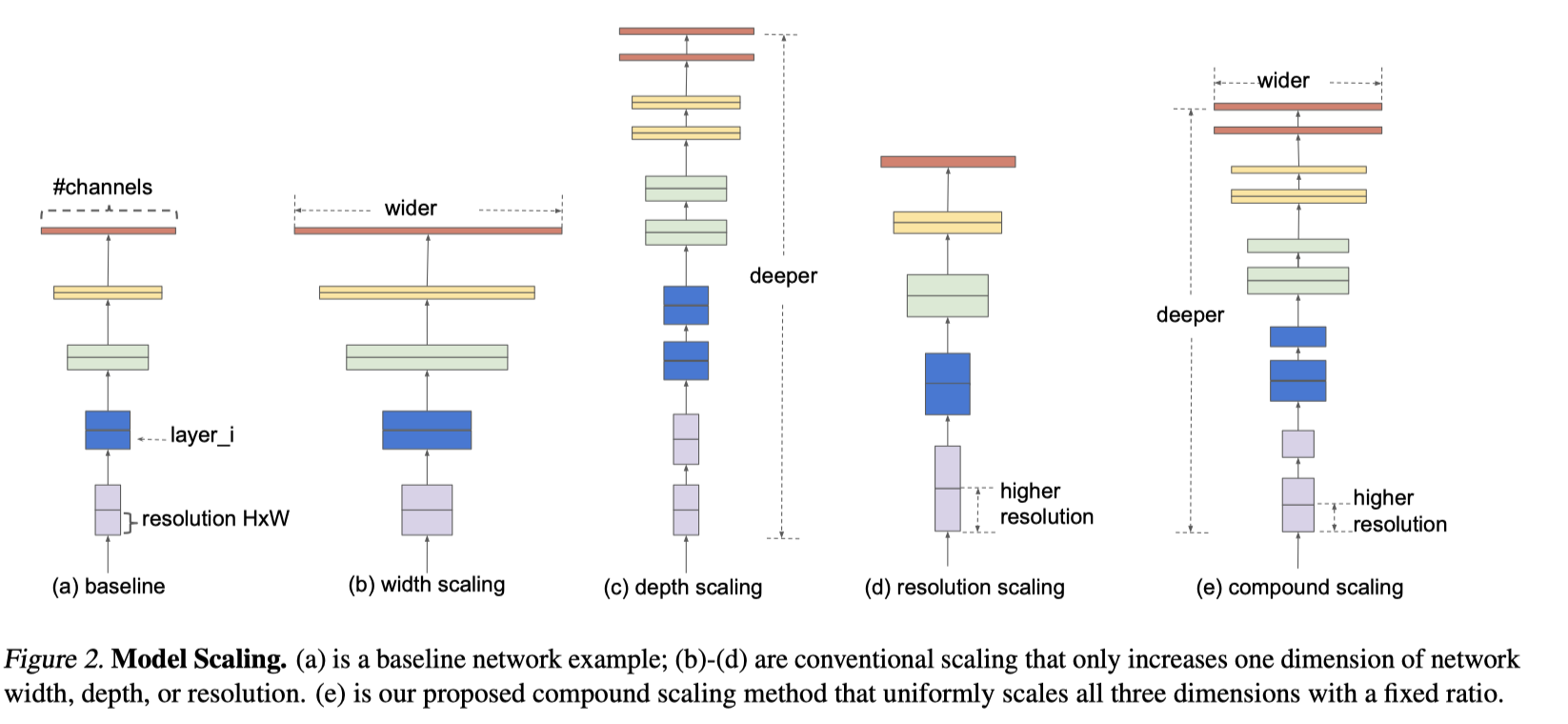
model scaling 示意图
深度、宽度和输入分辨率和模型精度的关系 如下图所示增加他们任何一项都可以提升模型的性能,但是也可以看到,只改变一项的话,模型性能很快就会饱和

Compound Scaling 深度、宽度和输入分辨率之间不是互相独立的,当增加输入分辨率时, 需要适当加深模型的深度以获得更大的感受野,同时需要增加模型的宽度,以从拥有更多像素的图像中提取更多 fine-gained patterns。 固定输入分辨率下,调整模型的深度和宽度,可以得到下面的图
 可以看到,当同时增大深度和宽度时模型更晚饱和,且获得了更高的性能,这验证了上面的猜想。
可以看到,当同时增大深度和宽度时模型更晚饱和,且获得了更高的性能,这验证了上面的猜想。基于此,作者提出了下面的 scaling 指导方法: $$\begin{array}{l}\text { depth: } d=\alpha^{\phi} \ \text { width: } w=\beta^{\phi} \ \text { resolution: } r=\gamma^{\phi} \ \text { s.t. } \alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2 \ \quad \alpha \geq 1, \beta \geq 1, \gamma \geq 1\end{array}$$ 方大系数乘积关系有的加平方有的没有平方是因为翻倍深度会使 FLOPS 也翻倍, 但是翻倍宽度和输入分辨率,FLOPS 会是 4 倍。 乘积限制为 2 左右是为了使最终的 FLOPS 增大为原来的 $2^\phi$ 倍。
EfficientNet EfficientNet 结构是参考 MnasNet 搜出来的,它的搜索目标是 $A C C(m) \times[F L O P S(m) / T]^{w}$ 其中 $\omega=0.07$ 是一个调整 acc 和 flops 的超参, T 是目标 FLOPS 最后搜出来的结果如下:
