YOLO9000: Better, faster, stronger 链接到标题
* Authors: [[Joseph Redmon]], [[Ali Farhadi]]
初读印象 链接到标题
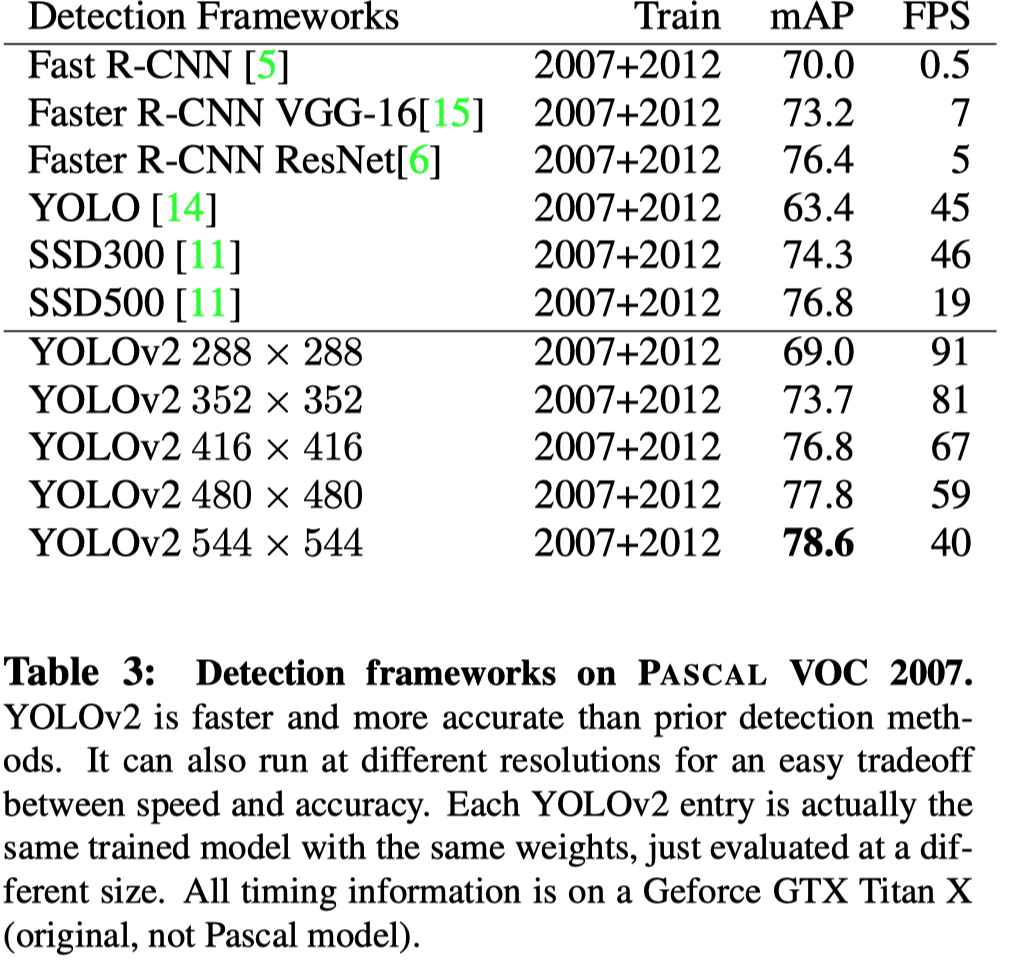
YOLOv2 引入 bn、anchor、新的 backbone、multi-scale training 等技术获得了相比 YOLOv1 更快效果更好的模型
文章骨架 链接到标题
%%创新点到底是什么?%% novelty:: 引入 bn、anchor、new network、multi-scale traing 等一系列 新技术获得了相比 YOLOv1 精度更高速度更快的 YOLOv2; 通过改变训练 pipeline ,定义一种 wordnet 的分类模式将检测和分类数据集结合用于检测模型的训练,得到了可以预测高达 9000 种类别的模型 YOLO9000。
%%有什么意义?%% significance:: 提升了一阶段检测器的速度和精度
%%有什么潜力?%% potential::
TL;DR 链接到标题
本文引入 bn、anchor、new network、multi-scale traing 等一系列 新技术获得了相比 YOLOv1 精度更高速度更快的 YOLOv2; 通过改变训练 pipeline ,定义一种 wordnet 的分类模式将检测和分类数据集结合用于检测模型的训练,得到了可以预测高达 9000 种类别的模型 YOLO9000。
动机 链接到标题
提升 YOLO 检测模型的精度、速度,并扩展适用物品类别。
方法 链接到标题
Better 链接到标题
这里的 Better 主要指通过引入一些技术手段在保证速度的前提下提高模型的检测精度。主要有
- Batch Normalization 加快收敛速度,丢掉 dropout 等 regularization, 基于 bn mAP 提升了 2%
- High Resolution Classifier YOLO 训练 backbone 用的 224x224 分辨率,但是测试的时候用的 448x448 的分辨率。 YOLOv2 把预训练的 backbone 在 448x448 分辨率下 fine tune 10 个 epoch 再用来训 detection。 这带来了 4% mAP 提升。
- Convolutional With Anchor Boxes 参考 Faster R-CNN,移除掉 YOLO 最后的几层 fc, 改为在 feature map 的每个位置预测 anchor boxes 的偏移量,这样能把框回归问题给简化。 虽然使用 anchor mAP 从 69.5% 略微掉到了 69.2%,但是 Recall 由 81% 上升到了 88%。 有几个细节需要提到,这里作者把输入分辨率由 448x448 调到了 奇数的 416x416 这样能够保证一张图只有一个中心。 因为作者认为物体尤其是大物体,有更高的概率出现在图像中心,一个anchor 来预测能减小干扰提升准确性。
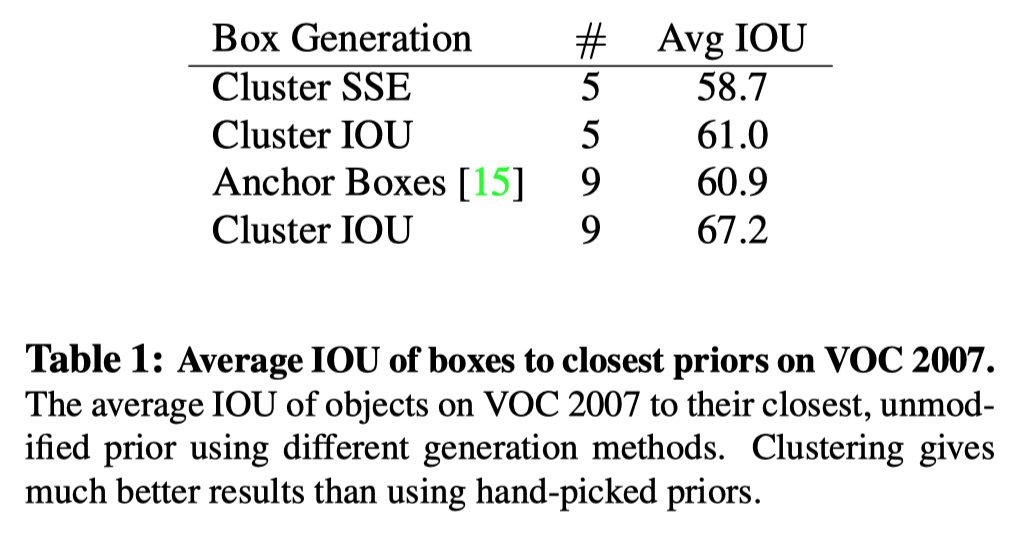
- Dimension Clusters
作者使用 k-means 来自动化地挑选 feature map 每个坐标点应该铺多少个 anchor,而以往都是人工设置的。
作者在训练集的所有 bounding boxes 上跑 k-means, 其中距离度量使用的是下面基于 IoU 的方式, 因为使用 L2 大框相对小框会得到更多的 loss, 且最终目标是得到更好的 IoU。
$$ d(\text { box }, \text { centroid })=1-\mathrm{IOU}(\text { box }, \text { centroid }) $$
最终选择 k=5 以达到精度和速度的平衡,同时作者发现自动挑选出来的 anchor 倾向于瘦高型的。
- Direct location prediction 对 location 的预测添加限制, 以消除训练的不稳定现象。如果按照 RPN 对框中心的预测: $$\begin{array}{l}x=\left(t_{x} * w_{a}\right)-x_{a} \ y=\left(t_{y} * h_{a}\right)-y_{a}\end{array}$$ 由于 $t_x, t_y$ 没有约束,这样会导致 anchor 跑到任何地方,造成训练不稳定。为此,YOLOv2 改为类似于 YOLO v1 那样预测相对 grid cell 的偏移, 这样能把 ground truth取值限定在 0 到 1 之间(通过 sigmoid 实现)。对每一个 bounding box,模型预测 $t_x, t_y, t_w, t_y, t_o$ 五个值。 假如当前 cell 相对图片左上角坐标为 $(c_x, c_y)$ , anchor 宽高为 $p_w$ 和 $p_h$ 那么 $$ \begin{aligned} b_{x} &=\sigma\left(t_{x}\right)+c_{x} \ b_{y} &=\sigma\left(t_{y}\right)+c_{y} \ b_{w} &=p_{w} e^{t_{w}} \ b_{h} &=p_{h} e^{t_{h}} \ \operatorname{Pr}(\text { object }) * I O U(b, \text { object }) &=\sigma\left(t_{o}\right) \end{aligned} $$ 基于 4 5 两个改进, anchor based 的方法能提高 5%。
- Fine-Grained Features 为了提高模型对小物体的预测能力,除了使用最后一层 13x13 的 feature map 之外,YOLOv2 还同时使用 26x26 那层的 feature, 在空间上将它切分成四块,然后 chanel 维度拼接起来,从 26x26x512 变成 13x13x2048, 然后和原始的 13x13 feature map 拼接起来起来进行后续步骤。该方法带来了 1% 的涨点。
- Multi-Scale Training
YOLOv2 每训练 10 个 epoch 就将输入分辨率调整为 {320, 352, …, 608} 其中之一(注意这些分辨率都是 32 的倍数,因为 YOLOv2 将输入 down sample 了 32 倍。)。这样,能够使一个模型适应各种各样的输入尺寸,当追求速度时使用小尺寸输入,当追求精度时使用大尺寸输入。
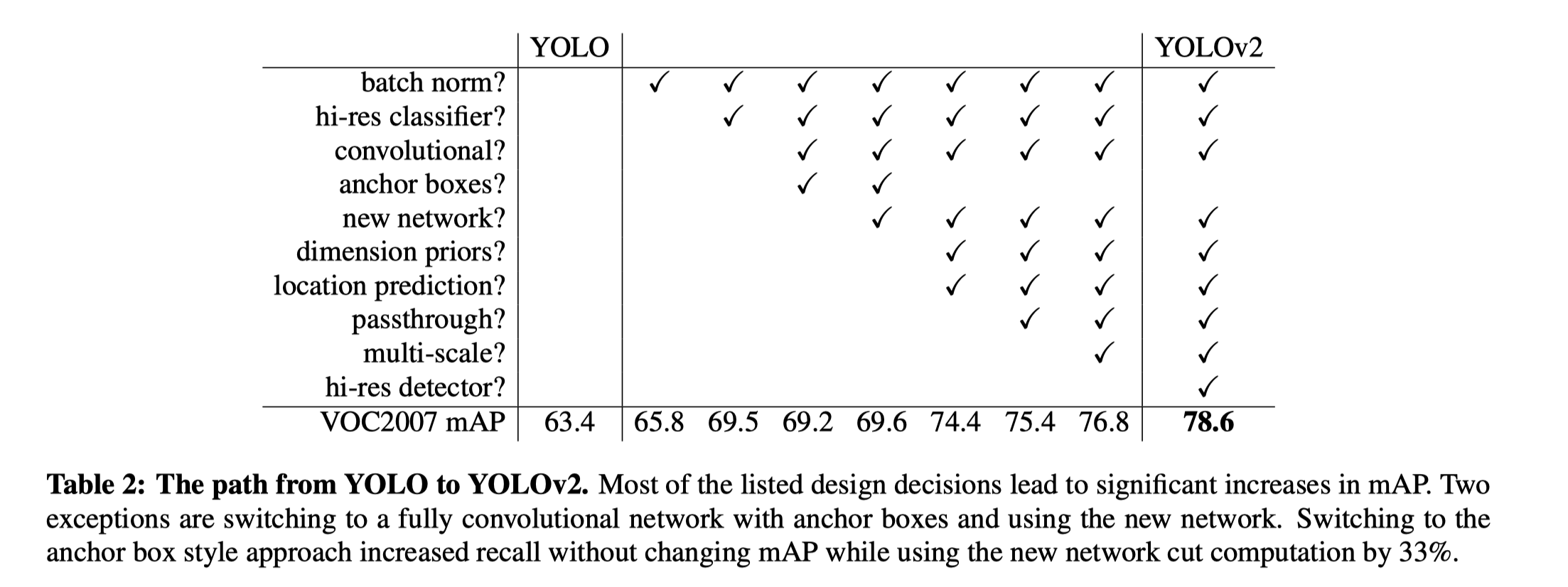
所有这些技术加入后对点数的影响如下表所示:
Faster 链接到标题
- Darknet-19
模型 operations top-1 acc top-5 acc VGG-16 30.69B 90.0% Darknet 8.52B 88.0% Darknet-19 5.58B 72.9% 91.2% 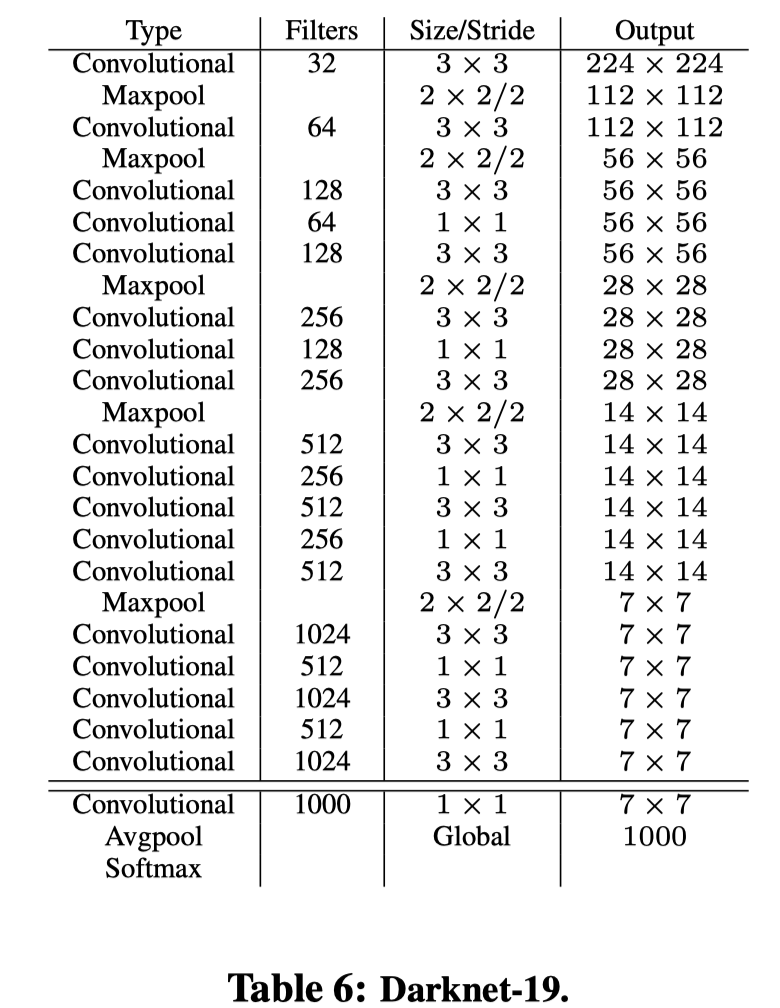
- Training for classification 在 ImagNet 上先 224x224 训练到收敛,然后 448x448 fine tune 10 个 epoch, top1 达到 76.5%, top-5 达到 93.3%。
- Training for detection
Stronger 链接到标题
同时使用检测数据集 COCO 和分类数据集训练,如果是带检测标注的数据则梯度回传所有 loss, 如果是分类数据,则只回流和分类有关的 loss。这带来了一个问题, 分类任务需要所有类别是不相交的,但是 COCO 和 ImageNet 有相交、集成关系, 比如 COCO 里的 dog 类别, 在 ImageNet 里有 “Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier” 等各种类别。
为了解决这个问题, 作者构造了一种 WordTree 的分类系统, 这样能把这些有交集的类别给统一到一个框架内(为了数量均衡,作者把 COCO 过采样了,ImageNet 和 COCO 的比例达到 4:1)。
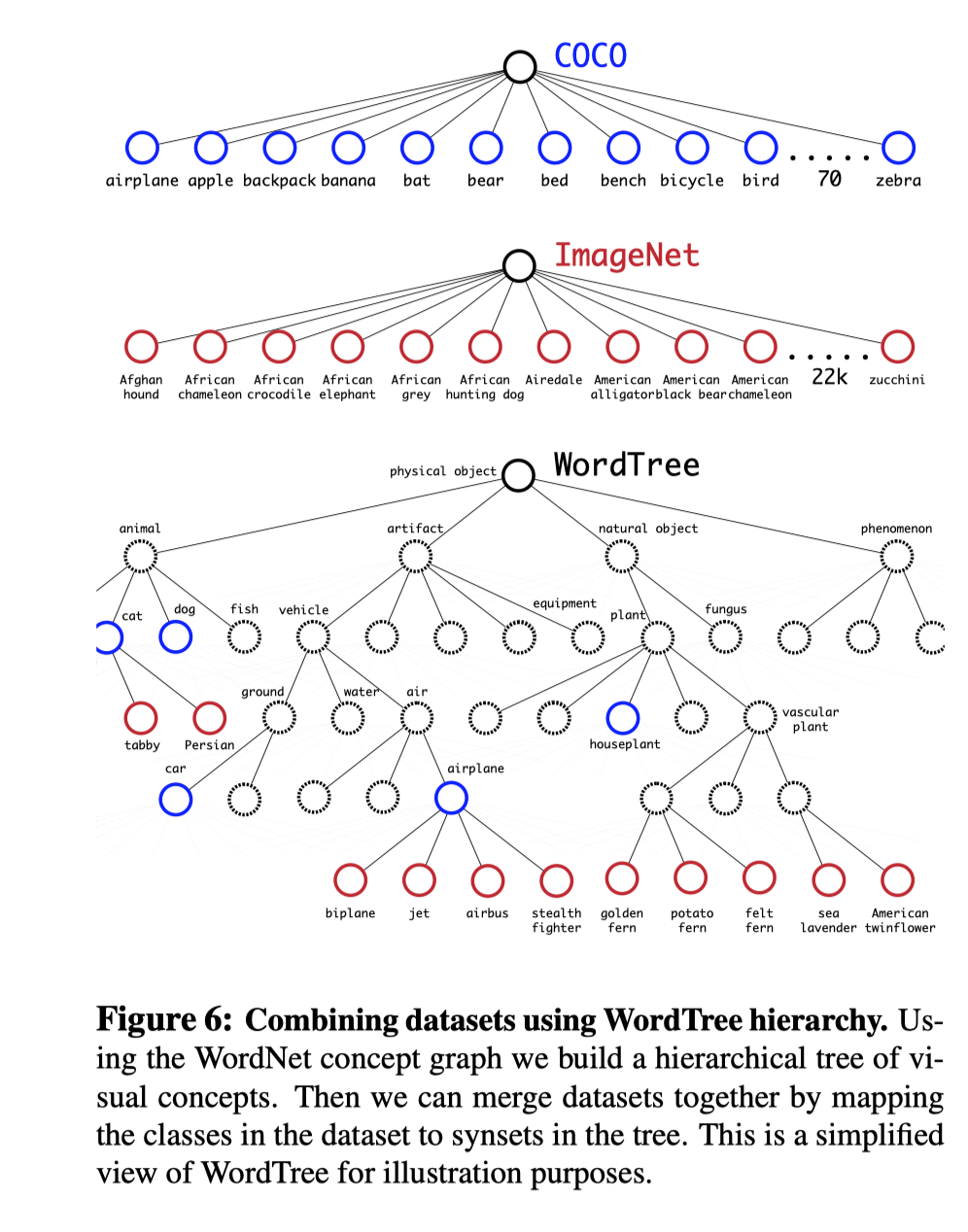 然后根据继承关系链式预测目标类别,比如:
然后根据继承关系链式预测目标类别,比如:

最终构造了能够预测 9000+ 类别的 YOLOv2。