Instant Neural Graphics Primitives with a Multiresolution Hash Encoding 链接到标题
* Authors: [[Thomas Müller]], [[Alex Evans]], [[Christoph Schied]], [[Alexander Keller]]
初读印象 链接到标题
instant-ngp 作者提出了一种可学习参数的多分辨率哈希编码结构替换 NeRF 中使用的三角函数频率编码,使得模型可以使用更小的 MLP 结构获得等效或者更好的结果。而更小的模型、多分辨率编码的高效并行以及纯 cuda 的原生加速实现, 使得 NeRF 的训练时间从小时级压缩到分钟级甚至是秒级。
文章骨架 链接到标题
%%创新点到底是什么?%% novelty:: 提出了一种可学习参数的多分辨率哈希编码结构替换 NeRF 中使用的三角函数频率编码,使得模型可以使用更小的 MLP 结构获得等效或者更好的结果
%%有什么意义?%% significance:: 使得 NeRF 的训练时间从小时级压缩到分钟级甚至是秒级
%%有什么潜力?%% potential:: 更高效的训练,助力 NeRF 在更多场景下落地
TL;DR 链接到标题
作者提出了一种可学习参数的多分辨率哈希编码结构替换 NeRF 中使用的三角函数频率编码,使得模型可以使用更小的 MLP 结构获得等效或者更好的结果。而更小的模型、多分辨率编码的高效并行以及纯 cuda 的原生加速实现, 使得 NeRF 的训练时间从小时级压缩到分钟级甚至是秒级。
输入编码的背景信息 链接到标题
对输入数据编码是一个很常见的课题, 我们在很多领域都可以看到,例如
- 在机器学习中, 我们常常会将低维输入映射到高维从而使复杂的数据结构呈现线性的性质,例如独热编码(one-hot encoding), 核方法(kernel trick)。
- 在 ViT 中, 输入编码也是不可获取的信息, 这里输入编码主要作用是告诉模型当前处理的数据在图像的具体位置,本质上起到一个注意力的机制。
在 NeRF 原文中, 我们用到的编码形式和 ViT 用到的很相似,都是采用三角函数形式的频率编码, 但是这儿不是用作样本位置提示的目的, 而是给输入引入高频信息, 让模型更好的学习到样本的细节。
稠密参数编码 链接到标题
最近的一些方法引入 grid、 tree 等额外的带参数的数据结构, 然后通过输入向量 $\mathbf{x}\in\mathbb{R}$ 查询和插值(可选)到这些参数作为输入编码的方式取得了 SOTA 的结果。这类方法虽然引入了更多的参数量, 但是在梯度更新的时候只会一小部分参数会被更新(以 3d grid 为例, 只会更新编码输入周围最近的 8 个点位的参数),所以训练时带来的额外 FLOPS 和内存增加地并不明显。 由于带参数的编码可以在输入进网络前提供更多的有效信息, 因此可以减小 MLP 模型的大小从而使保证质量的同时加快模型收敛速度。
稀疏参数编码 链接到标题
上面的稠密编码形式虽然带来了更高的精度和收敛速度,但是同时稠密的 grid 结构消耗的内存量远大于模型本身的权重, 考虑到
- grids 在接近物体表面以及空旷区域分配的特征数量是接近的,而grid的参数量和分辨率增长呈3次方的关系,而物体表面积增长和分辨率增长只有二次方关系,有大量参数是无用的。 例如对于分辨率为 128^3 的 grid 来说, 大约只有 2.57% 的 cells 会接触到可见表面。
- 稠密编码在一些场景下会呈现过于平滑的结果, 如图 2(d) 所示
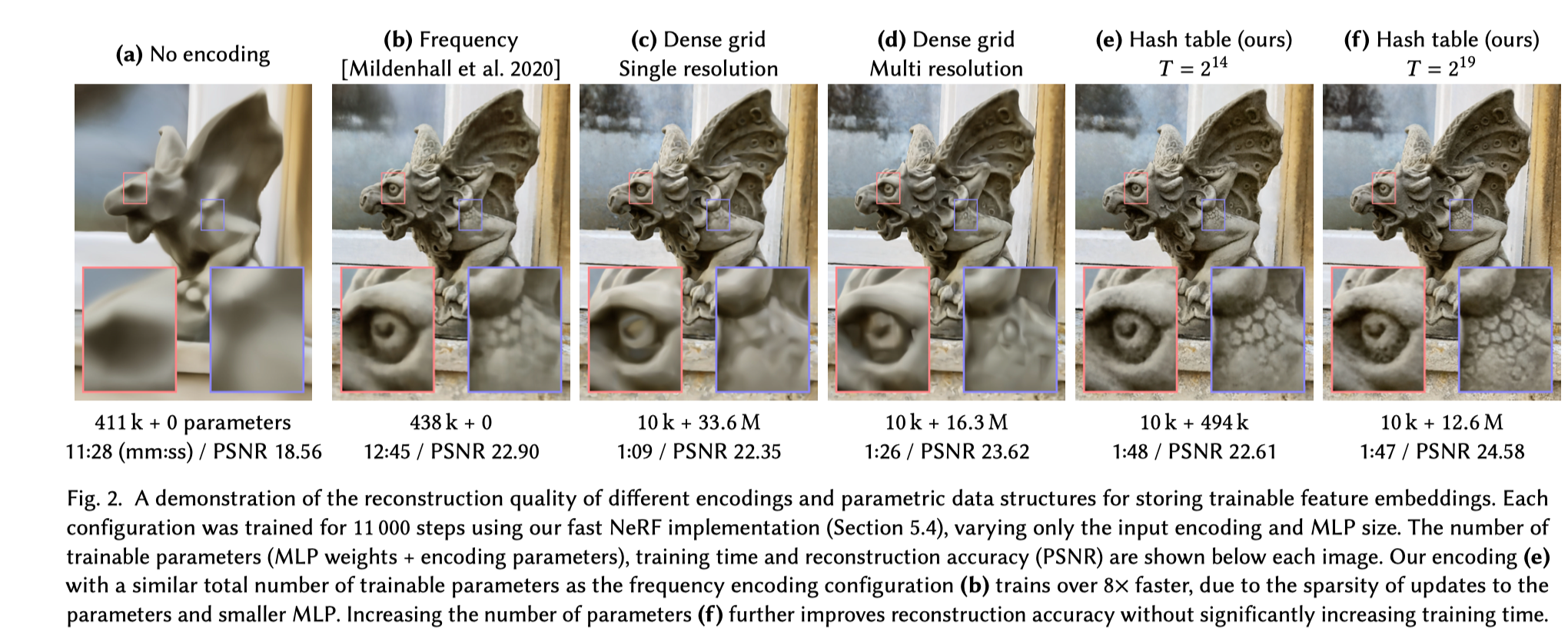
所以稠密参数编码是比较浪费资源的一种编码形式。
如果物体的表面信息是已知的, 那么可以用 octree 和 sparse grid 作为数据结构来避免浪费, 但是在 NeRF 场景下, 表面信息只有训练阶段可以拿到, 这会影响方法的适用性。
NSVF 等方法使用 coarse-to-fine 的多阶段形式, 根据 coarse 的稀疏网格下的结果判断重要性以在 refine 阶段细化或者剔除网格区域。这个方法比较高效, 但是由于要定期更新稀疏数据结构而使训练的复杂度明显增加。
instant-NGP 结合了上面两种避免浪费的方法的优点。
- 将可训练的 feature vector 存在建凑的稀疏哈希表内, 哈希表的大小用 $T$ 表示, 可以通过控制这个参数来权衡参数数量和重建的质量。
- 采用对应不同分辨率的多个哈希表模拟多分辨率的 grid, 然后将他们 concat 在一起作为输入
基于这个编码在仅用二十分之一的参数量下达到和稠密编码相同的重建质量。
另外一个重点是, 文中的哈希编码没有显式的使用分桶等方法处理碰撞而是让神经网络自动去处理, 这样避免了控制流,减少算法复杂度提高模型性能。
下面详细介绍文中的多分辨率哈希编码细节
多分辨率哈希编码 链接到标题
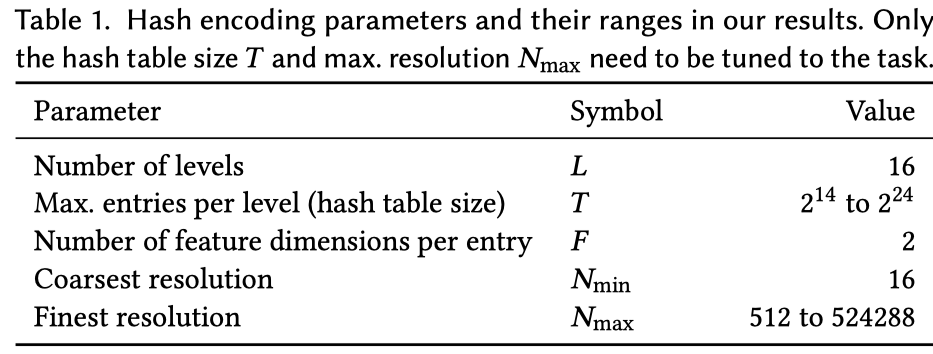
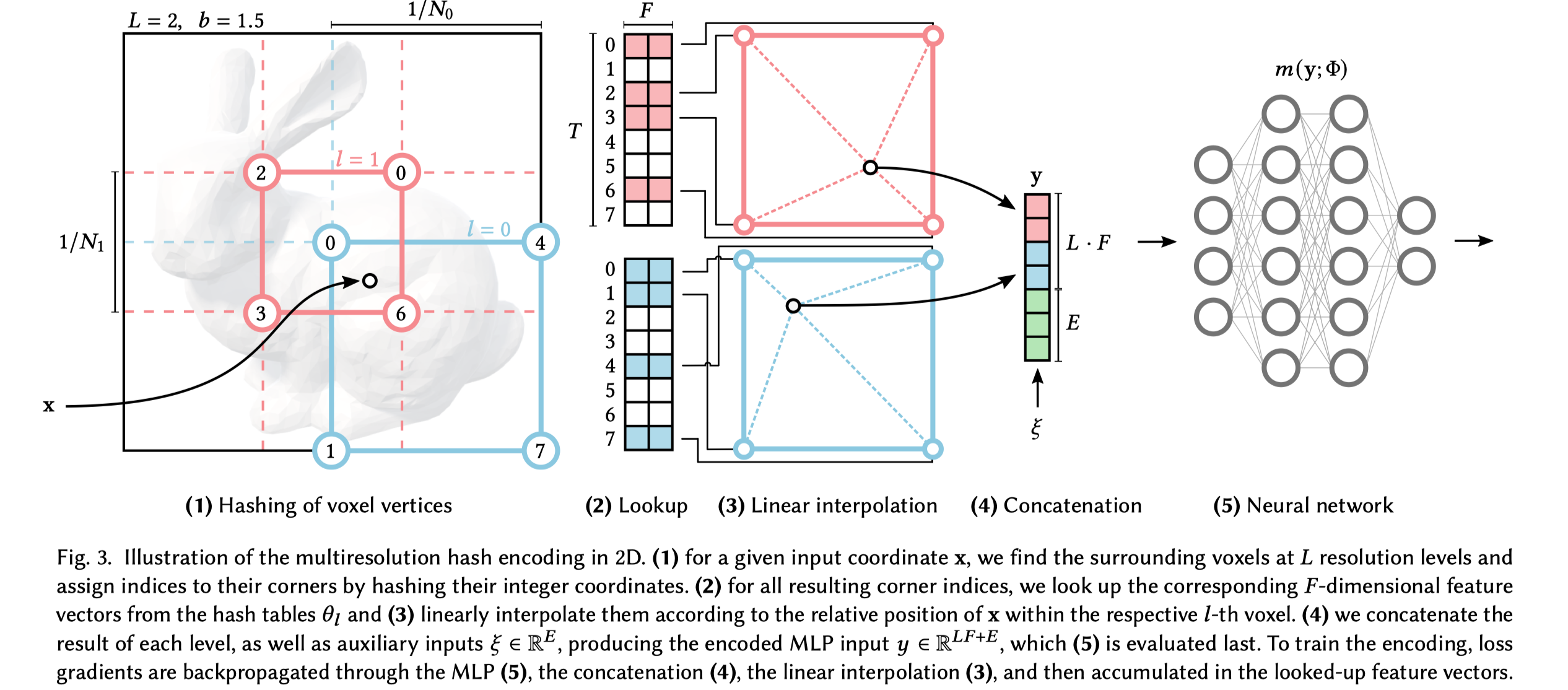
首先我们用 $m(\mathbf{y}; \Phi)$ 表示 MLP 模型, 编码方案用 $\mathbf{y} = enc(\mathbf{x}; \theta)$ 表示。 文中用到的一些超参以及典型的取值如表1所示, 详细步骤如图 3 所示。
首先将分辨率分成 $L$ 个等级的分辨率, 每个等级下最多有 $F$ 个 feature vector, 每个 feature vector 维度是 $F$ , 每个 feature vector 存储在 grid 定点上。 每层的分辨率是从 $N_{min}$ 到 $N_{max}$ 之间的等比级数,具体取值方法是:
$$ \begin{aligned} N_l &:=\left\lfloor N_{\min } \cdot b^l\right\rfloor \ b &:=\exp \left(\frac{\ln N_{\max }-\ln N_{\min }}{L-1}\right) \end{aligned} $$
由于层级比较多, b 的取值范围一版为 $[1.26, 2]$ 。 输入坐标 $\mathbf{x} \in \mathbb{R^d}$ 到对应层级前会乘以 grid 分辨率得到 $x_l = x\cdot{N_l}$ , 上下取整得到对应的 grid 顶点 $\left\lceil\mathbf{x}_l\right\rceil:=\left\lceil\mathbf{x} \cdot N_l\right\rceil$ $\left\lfloor\mathbf{x}_l\right\rfloor:=\left\lfloor\mathbf{x} \cdot N_l\right\rfloor$ 。
在粗分辨率下, 每个 grid 的顶点都能对应到唯一的 T 个 feature map 中的一个, 但是在细分辨率下, grid 的顶点数明显要大于 T, 此时需要 hash 函数 $h: \mathbb{Z}^d \to \mathbb{Z}_T$ 把顶点映射到 T 个 feature map。这里选用的 hash 函数是
$$ h(\mathbf{x})=\left(\bigoplus_{i=1}^d x_i \pi_i\right) \quad \bmod T $$
其中 $\bigoplus$ 表示按位异或, $\pi_i$ 是不重复的大质数。为了保证伪独立, 只有 d-1维需要 permute, 因此选择 $\pi_1:=1, \pi_2=2654435761, \pi_3=805459861$ 。
这个 hash 函数没有显式地处理碰撞问题, 而是让神经网络在反向传播的时候自动处理。
经过上面的映射, 每个坐标都会对应到 grid 的四个顶点, 每个顶点对应 1 个 F 维(文中 F = 2)的 feature map, 也就是每个坐标对应 4 个 feature map, 然后使用 $\mathbf{w}_l:=\mathbf{x}_l-\left\lfloor\mathbf{x}_l\right\rfloor$ 对他们加权求和得到 2 维的合并结果。 最后 $L$ 个级别的结果以及额外的输入 $\xi\in{\mathbb{R}^E}$ (例如视角方向、纹理等) 被 concat 到一起得到编码后结果 $\mathbb{y}\in{\mathbb{R}^{LF+E}}$
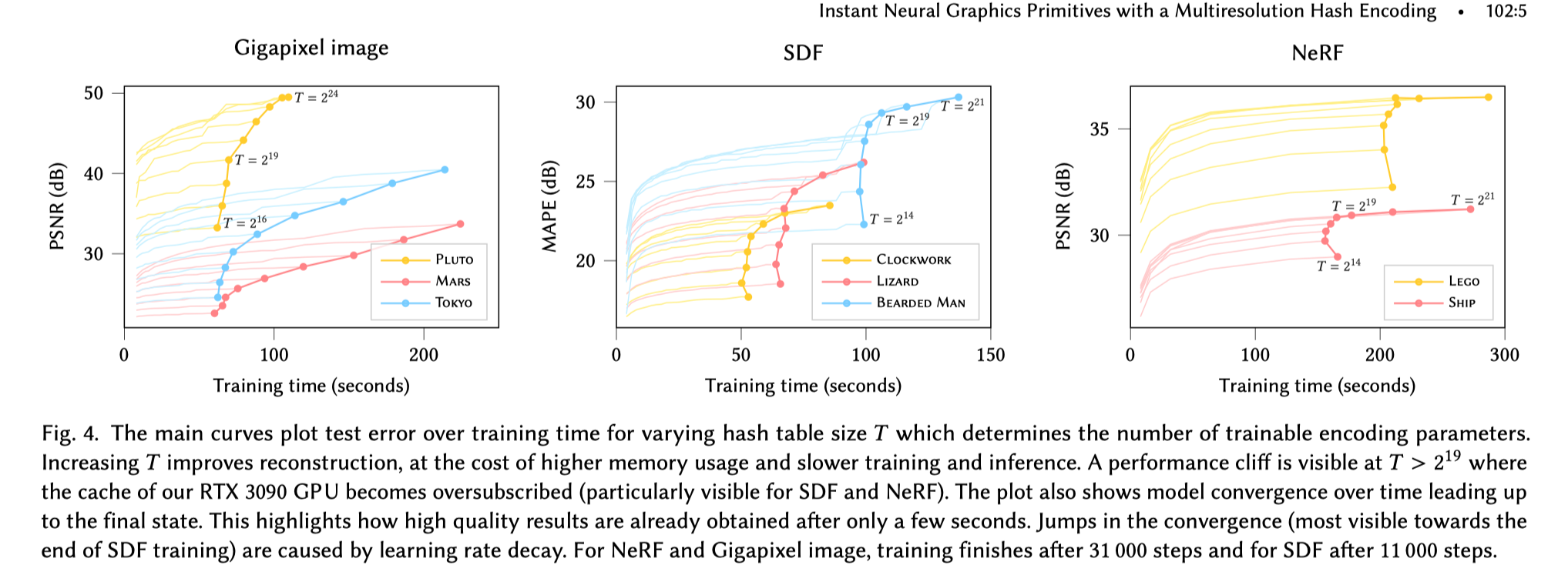
如图 4 所示, 哈希编码的长度 $T$ 会影响重建的效率和质量, 可以根据实际需求来调整合适的值。
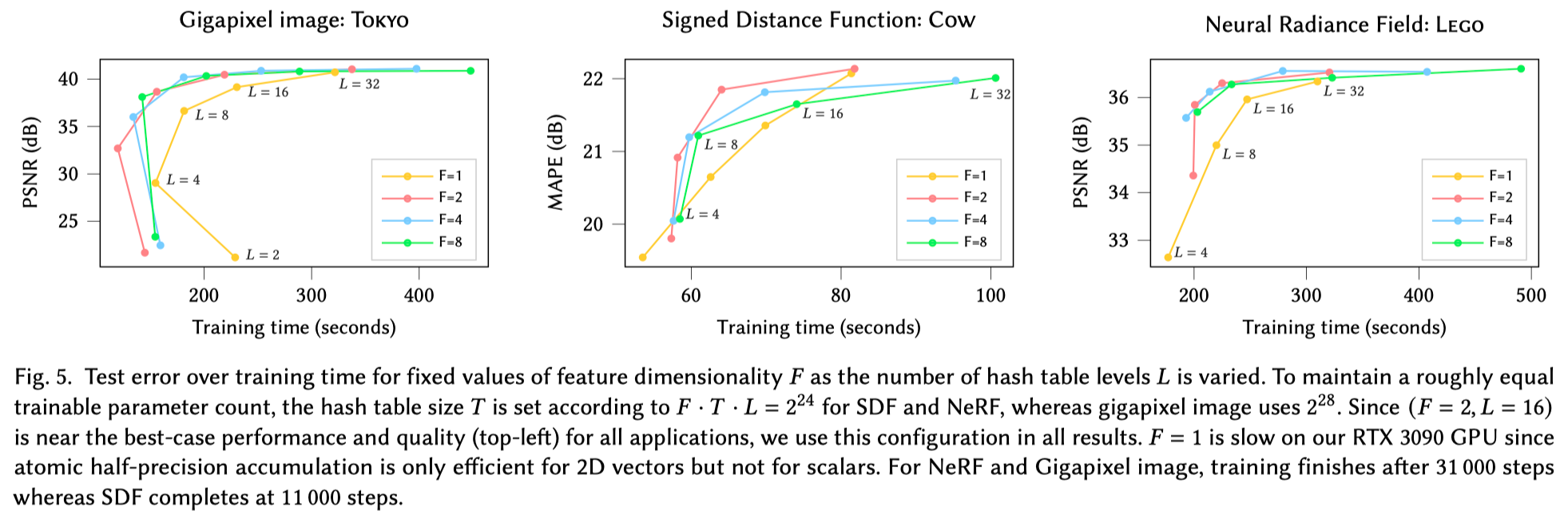
如图 5 所示, 分辨率级数 $L$ 和 feature vector 的维度 $F$ 也会对重建效果和质量权衡, 但是实验发现,当选择 $F=2, L=16$ 时,在作者尝试的所有任务上都达到了比较好的权衡结果,所以后面的实验这俩值保持这个数值不变。
另外举个例子来说明为什么可以用神经网络的优化来进行哈希的碰撞处理:假设一个接近物体表面的点和一个空旷区域的点被 hash 到了相同的 grid 顶点, 但是我们知道接近物体表面的点是模型更加关心的, 优化的时候这个点会带来更大的梯度, 从而顶点参数更新会由这个点来主导, 这样就间接地处理好了碰撞的问题。
实现细节 链接到标题
性能考量 链接到标题
- 哈希表用半精度存储, 同时维护一个全精度的版本用于混合精度参数更新。
- 为了优化 GPU 的缓存使用, 逐级查找输入在对应层级分辨率 grid 的位置, 这样每次只有少量的 hash 表需要常驻 cache。
架构优化 链接到标题
- 处理 NeRF 任务外, 其他的所有 MLP 都只用 2 层,每层 64 个单元
初始化 链接到标题
- 所有的 hash 表都用 $\mathcal{U}(-10^{-4}, 10^{-4})$ , 这样可以保证在提供合理的随机值同时值接近 0 。
训练 链接到标题
- 使用 Adam 同时训练模型参数和哈希表, $\beta_1=0.9, \beta_2=0.99, \epsilon=10^{-15}$
实验 链接到标题
作者在 Gigapixel Image Approximation、Signed Distance Functions、Neural Radiance Caching、Neural Radiance and Density Fields (NeRF) 四个任务上进行了实验, 在收敛速度明显的提升的前提下获得了不错的精度, 详细结果可以在论文上查看
smaller network that significantly reducing the number of floating point and memory access operations 1. augmented by a multiresolution hash table 2. The multiresolution structure allows the network to disambiguate hash collisions, trivial to parallelize on modern GPUs
Introduction 链接到标题
- encoding that maps neural network inputs to a higher-dimensional space, which is key for extracting high approximation quality from compact models. This enables the use of smaller, more efficient MLPs
- multiresolution hash encoding, which is adaptive and efficient, independent of the task.
- configured by just two values—the number of parameters $T$ and the desired finest resolution $N_{max}$
- Adaptivity: we map a cascade of grids to corresponding fixedsize arrays of feature vectors.
- Efficiency: our hash table lookups are O(1) and do not require control flow.
BACKGROUND AND RELATED WORK 链接到标题
- encoding the inputs of a machine learning model into a higher-dimensional space (one-hot encoding, kernel trick, etc..) making complex arrangements of data linearly
- encodings in neural network have proven useful in the attention components, because they help the neural network to identify the location it is currently processing
- parametric encodings: arrange additional trainable parameters (beyond weights and biases) in an auxiliary data structure, trades a larger memory footprint for a smaller computational cost
- sparse parametric encodings
downsides of dense encodings:
- it allocates as many features to areas of empty space as it does to those areas near the surface
- natural scenes exhibit smoothness
our method combines both ideas to reduce waste
- store the trainable feature vectors in a compact spatial hash table
- use multiple separate hash tables indexed at different resolutions whose interpolated outputs are concatenated before being passed through the MLP
we rely on the neural network to learn to disambiguate hash collisions itself,
MULTIRESOLUTION HASH ENCODING 链接到标题
$$ \begin{aligned} N_l &:=\left\lfloor N_{\min } \cdot b^l\right\rfloor \ b &:=\exp \left(\frac{\ln N_{\max }-\ln N_{\min }}{L-1}\right) \end{aligned} $$
$b \in [1.26, 2]$
References 链接到标题
- 10.2312/EGWR/EGSR07/051-060
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1007/978-3-030-58526-6_36
- This reference does not have DOI 😵
- 10.1109/CVPR42600.2020.00700
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1145/1185657.1185834
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1145/3478513.3480569
- 10.1016/B978-0-12-394424-5.00002-1
- 10.1145/1730804.1730831
- 10.1109/CVPR42600.2020.00604
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1145/3450626.3459785
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1145/3306346.3322980
- 10.1007/978-3-030-58452-8_24
- This reference does not have DOI 😵
- 10.1145/3341156
- 10.1145/3414685.3417804
- 10.1145/3450626.3459812
- 10.1145/2487228.2487235
- 10.1145/3450623.3464653
- 10.1111/cgf.14340
- 10.1145/2508363.2508374
- 10.1109/TVCG.2003.1196006
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1007/978-3-030-58580-8_31
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1109/CVPR46437.2021.01120
- This reference does not have DOI 😵
- 10.1145/3272127.3275096
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- This reference does not have DOI 😵
Currently 0 references inside library! @2022-12-28