Pixel-in-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild 链接到标题
* Authors: [[Haibo Jin]], [[Shengcai Liao]], [[Ling Shao]]
初读印象 链接到标题
PIPNet 提出了一种粗粒度heatmap之后细粒度回归的关键点检测算法,结合了 heatmap方法高精度和回归方法高速度的优点,在多个bmk上取得了很好的效果。
文章骨架 链接到标题
%%创新点到底是什么?%% novelty:: 结合了 heatmap 和 regression 的优点,达到又快又好的关键点检测效果
%%有什么意义?%% significance:: 保证 heatmap 类方法高精度的同时保证了推理速度。
%%有什么潜力?%% potential::
TL;DR 链接到标题
当前主流的 landmark 检测方法主要有两类, 一类基于 heatmap 的,如图3(b) 所示,一类直接回归坐标,如图3(a)所示。 heatmap 方法优点是准确性高,缺点是计算复杂度高、缺少全局约束(表现如被遮挡区域预测不受控制), 而直接回归坐标的方法计算复杂度低且有比较好的全局形状约束,但是精度相对较低。
本文提出一种名为 PIPNet 的方法, 希望结合两类方法的优点。
计算复杂度问题 链接到标题
首先, 为了解决 heatmap 方法计算复杂度高的问题, PIPNet 取消了上采样过程,直接在下采样后的 $N\times{W_I/s}\times{H_I/s}$ s 为 stride,N 为landmark 数目, $W_I,H_I$ 分别为输入分辨率,比如输入 256x256 的数据,s = 32, 那么获得的 feature map 大小为 8x8,通过 feature map 上最大值定位当前关键点的粗糙位置,显然这个分辨率的 faeture map 只对应 64 个位置是不足以应对 landmark 检测任务的, 为此, 作者额外增加了一个 $2\times{N}$ 的分支 offset 预测分支, 这个分支的输出是以粗糙位置所在的 grid 的左上角为基准的精细位置。具体结构如图 3(c) 所示,而坐标形式的 gt 映射到新结构的过程如图 4 所示。
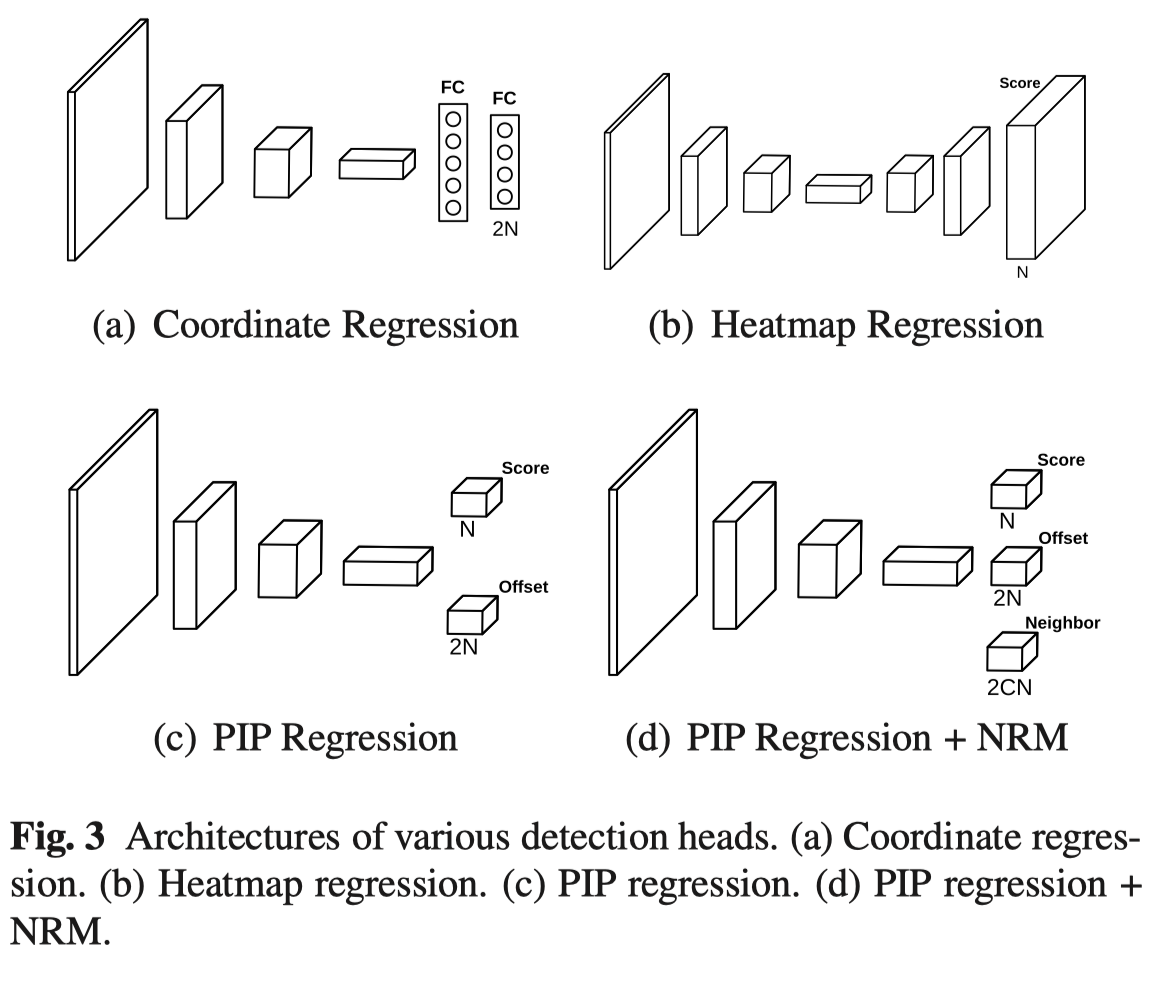

全局信息感知能力 链接到标题
如图 5 所示,当人脸角度很大时,PIPNet 和 feature map 预测一样会存在很大的偏差。这是因为坐标回归方法输出来源于 fc, 所有点的feature 能互相感知到, 但是 PIPNet 各个点是相互独立获取的,缺乏这样的全局信息。

为了提升模型的全局感知能力,在上面模型的基础上,作者提出了 neighbor regression module (NRM) 模块,在预测本身的 offset 以外, 这个分支还会预测当前点周围最近的 C 个点的 offset。 neighbors.
泛化能力问题 链接到标题
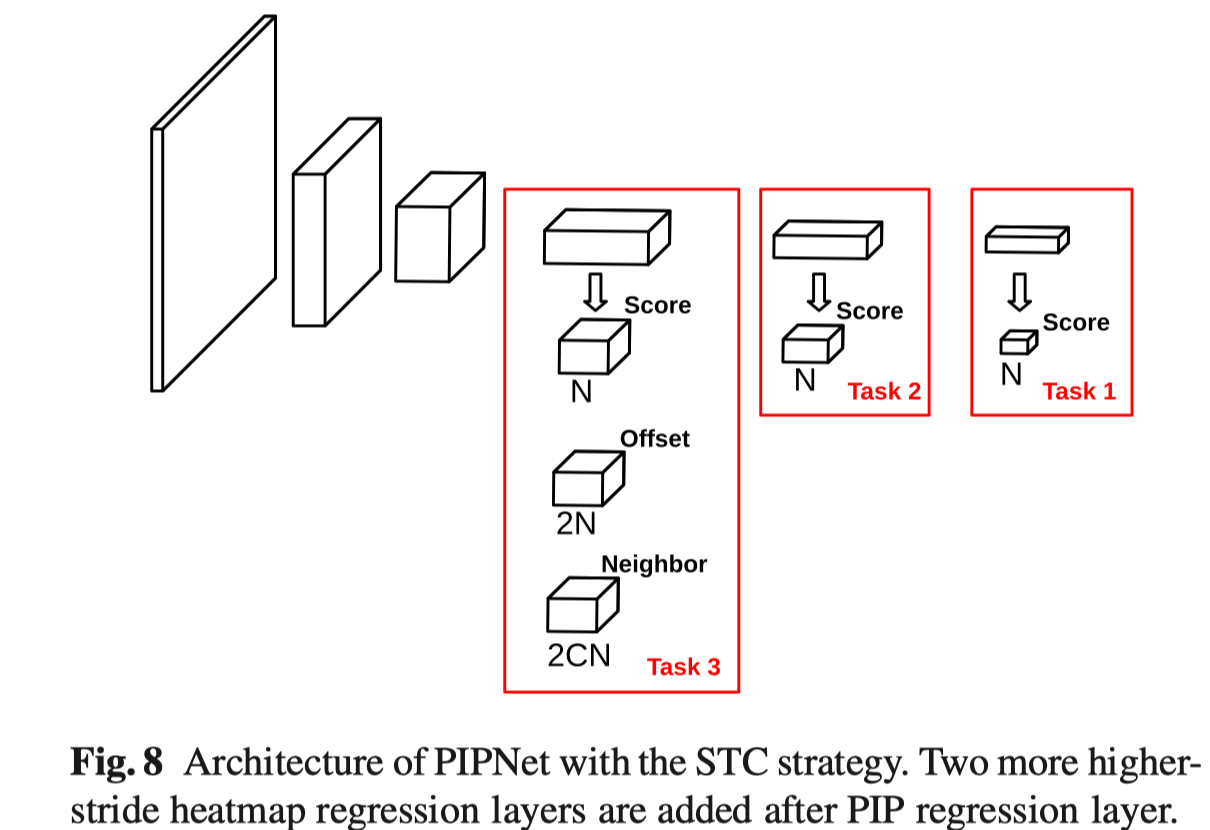
为了提升模型的泛化能力,提出了 self-training with curriculum (STC) 自学习模块, 和传统自学习一直针对一个任务进行不同, STC 会基于异源数据从难到易的三个任务学习。具体来说三个任务不同之处是 feature map 对应的 stride 不同, 也就是对应的分辨率不同,越大的 stride 对应的分辨率越低, 存在的负样本数量越少,也即任务越简单。
具体步骤:

- 用人工标注的图片训练 PIPNet;
- 用上一步得到的模型生成未标注数据的伪标签;
- 使用标注和伪标签生成新的数据集;
- 用人工数据集训练 task3, 新数据集训练 task 1- 2 重复 2-4 步骤
References 链接到标题
- 10.1109/BTAS.2017.8272731
- 10.1145/1553374.1553380
- 10.1109/ICCV.2013.191
- 10.1109/CVPR42600.2020.00590
- 10.1007/978-3-319-46454-1_8
- [[@chenFaceAlignmentKernel2019]]
- 10.1109/CVPR.2018.00352
- [[@dapognyDeCaFADeepConvolutional2019]]
- 10.1007/s11263-018-1134-y
- 10.1109/CVPR42600.2020.00525
- 10.1109/CVPR.2018.00110
- 10.1109/ICCV.2019.00087
- 10.1109/CVPR.2018.00047
- 10.1109/CVPR.2017.392
- [[@fengWingLossRobust2018]]
- This reference does not have DOI 😵
- This reference does not have DOI 😵
- 10.1109/CVPR.2014.306
- 10.1109/CVPRW.2017.255
- 10.1109/CVPR.2016.619
- 10.1109/CVPR.2018.00167
- 10.1109/ICCV.2019.00140
- This reference does not have DOI 😵
- 10.1109/CVPR.2019.00503
- 10.1109/ICCV.2017.409
- This reference does not have DOI 😵
- 10.1109/ICCVW.2011.6130513
- [[@kumarLUVLiFaceAlignment2020]]
- 10.1109/TPAMI.2012.191
- 10.1109/TPAMI.2017.2734779
- 10.1109/CVPR.2017.713
- 10.1109/ICCV.2015.425
- 10.1109/CVPR.2019.00358
- This reference does not have DOI 😵
- 10.1109/CVPR.2017.393
- 10.1109/CVPR.2018.00088
- 10.1007/978-3-319-46484-8_29
- 10.1109/CVPR.2017.395
- 10.1007/978-3-030-01264-9_17
- 10.1109/CVPR.2016.146
- 10.1109/ICCV.2019.01025
- 10.1109/TIP.2016.2518867
- 10.1109/ICCV.2019.01020
- 10.1007/978-3-319-24574-4_28
- 10.1109/ICCVW.2013.59
- 10.1109/CVPR.2019.00712
- 10.1109/CVPR.2018.00474
- 10.1109/ICCVW.2015.132
- 10.1109/CVPR.2013.446
- [[@taiHighlyAccurateStable2019]]
- 10.1109/CVPR.2014.220
- 10.1007/978-3-030-01219-9_21
- 10.1109/CVPR.2016.262
- 10.1109/CVPR.2016.453
- [[@valleDeeplyInitializedCoarsetofineEnsemble2018]]
- 10.1016/j.cviu.2019.102846
- This reference does not have DOI 😵
- 10.1109/ICCV.2019.00707
- 10.1109/CVPR.2016.511
- 10.1109/CVPRW.2017.261
- [[@wuLookBoundaryBoundaryAware2018b]]
- 10.1007/978-3-030-01231-1_29
- 10.1109/CVPRW.2017.253
- 10.1109/CVPR.2016.596
- 10.1109/ICCV.2017.113
- 10.1109/CVPR.2019.00225
- 10.1109/CVPRW.2017.263
- 10.1109/TPAMI.2015.2469286
- 10.1007/978-3-030-58621-8_31
- 10.1007/978-3-030-01261-8_11
- 10.1109/CVPR.2019.00360
- This reference does not have DOI 😵
- 10.1109/CVPR.2016.371
- 10.1109/CVPR.2019.00078
- 10.1109/ICCV.2019.00023
Currently 7 references inside library! @2022-12-28