BERT: Pre-training of deep bidirectional transformers for language understanding 链接到标题
* Authors: [[Jacob Devlin]], [[Ming Wei Chang]], [[Kenton Lee]], [[Kristina Toutanova]]
初读印象 链接到标题
BERT 使用无监督方案,不需要人工标注数据只需要在训练时使用上下文mask,以及下一句预测loss就能得到强大的语言预训练模型。

文章骨架 链接到标题
novelty:: 1. 在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。使模型被迫增加对上下文的记忆。2. 增加了一个预测下一句的loss。
significance:: 在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
potential:: BERT为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。

BERT 是近年来 NLP 领域最重大的改进之一。通过在大量无标签语料上无监督 pre-train 结合特定任务数据上 finetune 的学习范式, 实现一个模型吃遍天下的梦想,在许多任务上获得了质的提升, 比如提升 GLUE 7.6 个点, MultiNLI 提升 5.6 个点。

输入表示 链接到标题
为了适应各种类型的下游任务, BERT 做了如下工作:
- 为了支持情感分类等任务,在每个 token sequence 前面增加一个特殊的 token ([CLS]), 它对应的最后一个隐层输出接上 softmax 就是该句子的类别概率了。
- 为了支持问答等双输入的任务, 当输入为句子对时,使用一个特殊的 token ([SEP]) 来切分两个句子的同时在输入 embedding 上叠加一个可学习的 segment embeddings 来区分每一个 token 属于哪个句子。
所以,模型最后的输入由 token embeddings、segment embeddings 和 position embeddings 三个部分组成:
预训练阶段 链接到标题
在 nlp 领域内,存在着近乎无穷的未标注数据,如何从这些未标注信息提取有用的信息非常关键。BERT 通过设立一个由两个非监督子任务组成构成的预训练阶段来达到这个目的。 其中第一个任务 masked LM 基于上下文预测 mask 掉的 token, 第二个任务预测语句之间的相对位置。
- masked LM 不同于传统的从前到后预测或者从后到前的预测,BERT 通过 mask 掉句子中的部分 token 然后通过全部的上下文预测mask掉的句子,这是一种利用了双向信息的预测方式。 例如,给定句子 “我今天想要早点下班回家吃饭”,遮盖掉 “下班”,从前往后预测就是通过“我今天想要早点” 来预测被遮盖的“下班”, 从后往前预测就是通过"吃饭/回家" 来预测“下班”,而 BERT 的双向预测则是通过 “我今天想要早点[masked]回家吃饭"来预测“下班”, 显然,这种预测方式会比上面的方式有效的多。 具体实现上,全部语料中 15% 的 token 会被选中, 然后被选中的 token 有 80% 的概率被替换成 [MASK] token、10%的概率被随机替换成其他 token、10% 的概率保持原样。这么做的目的是防止被 mask 的 token 不存在于 finetune 任务数据中的情况。
- Next Sentence Prediction (NSP) 问答、自然语言推断等任务往往需要两两语句之间的关系,为了使模型在无监督条件下获取判断语句关系的能力,作者挑选了一些语句对,其中 50% 是有先后顺序关系的, 其他 50% 是预料库中随机挑选的没有顺序关系的,然后将语句对送进模型训练,并使用上一节提到的 [CLS] 编码对应的输出用于语句顺序关系的二值判断。
Fine-tuning BERT 链接到标题
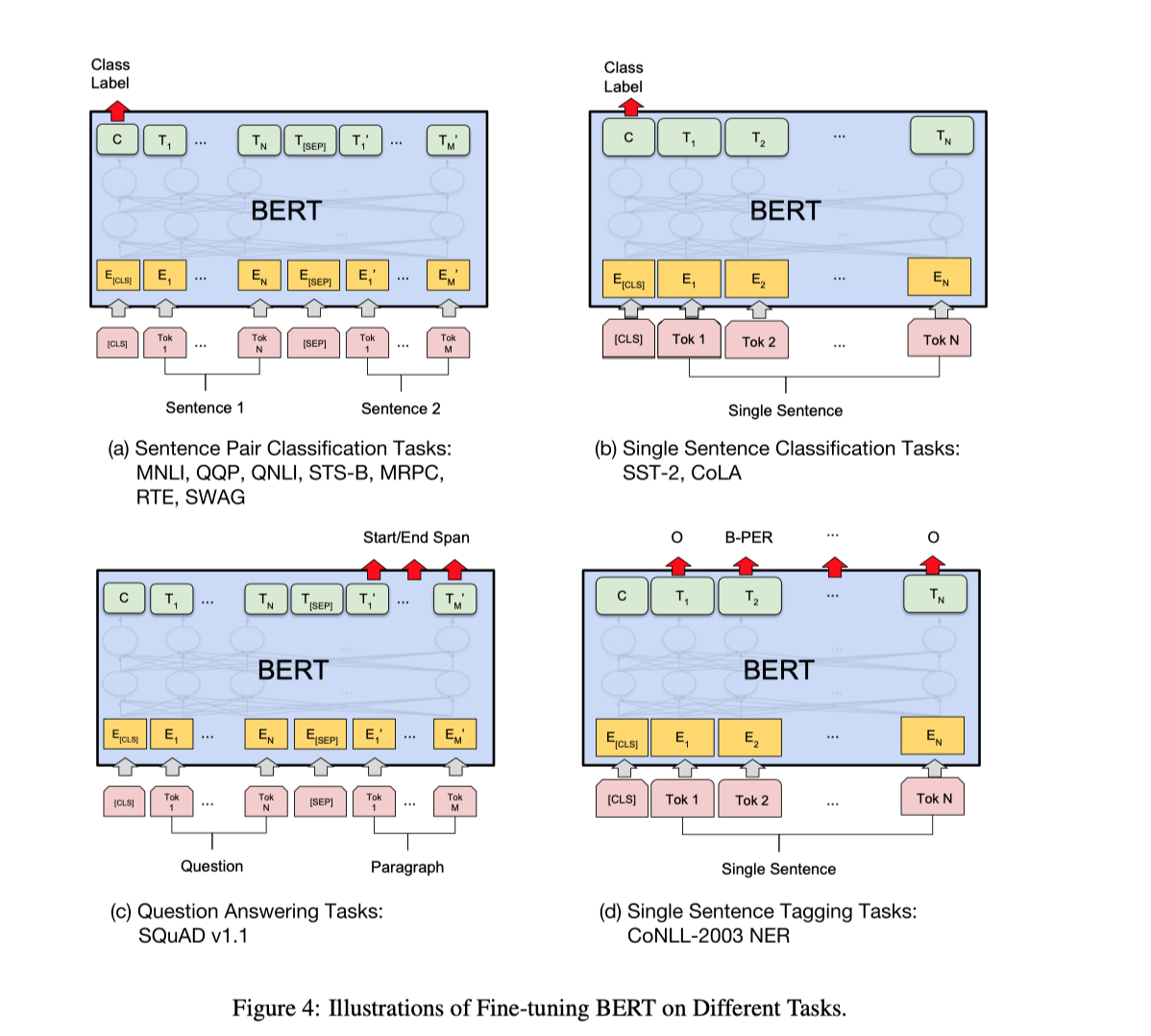
基于无监督学习得到的预训练模型需要使用目标任务对应的数据进行 finetune,如图4所示,将句子对或单个句子输入到模型,将 [CLS] token 对应的输出用于需求或情感分析,将其他 token 的输出用于序列标记、QA 任务。 相对于 pretrain 基于 finetune 最大的好处是基于预训练模型能极大减少特定任务模型训练需要的时间和资源,论文中的所有结果都可以在单TPU上1个小时内复现。
实验结果 链接到标题
- GLUE
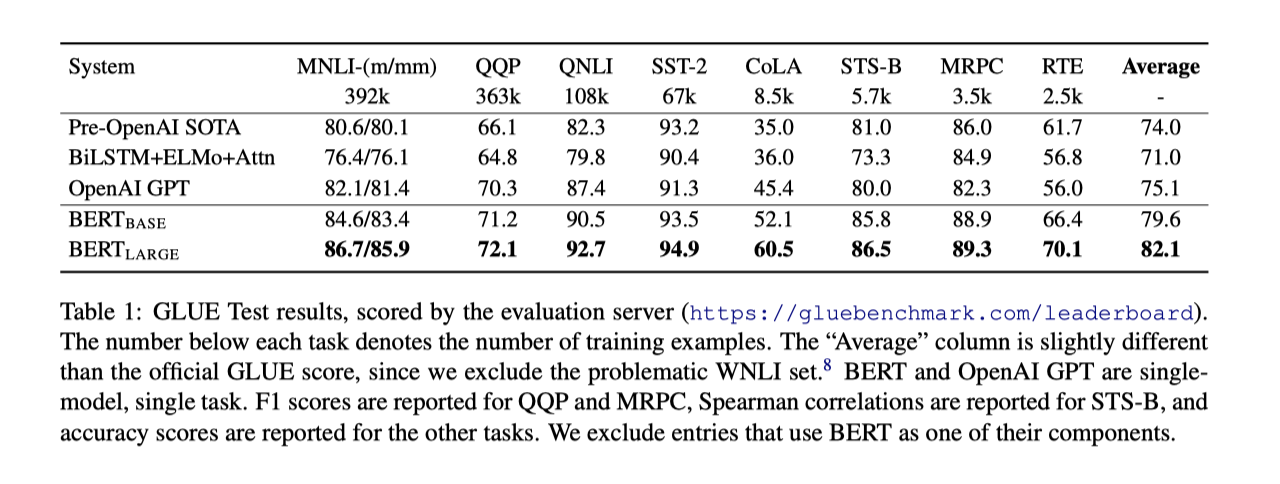 BERT base 和 large 模型相对之间的 SOTA 模型提升了 4.5% 和 7%。
BERT base 和 large 模型相对之间的 SOTA 模型提升了 4.5% 和 7%。 - SQuAD
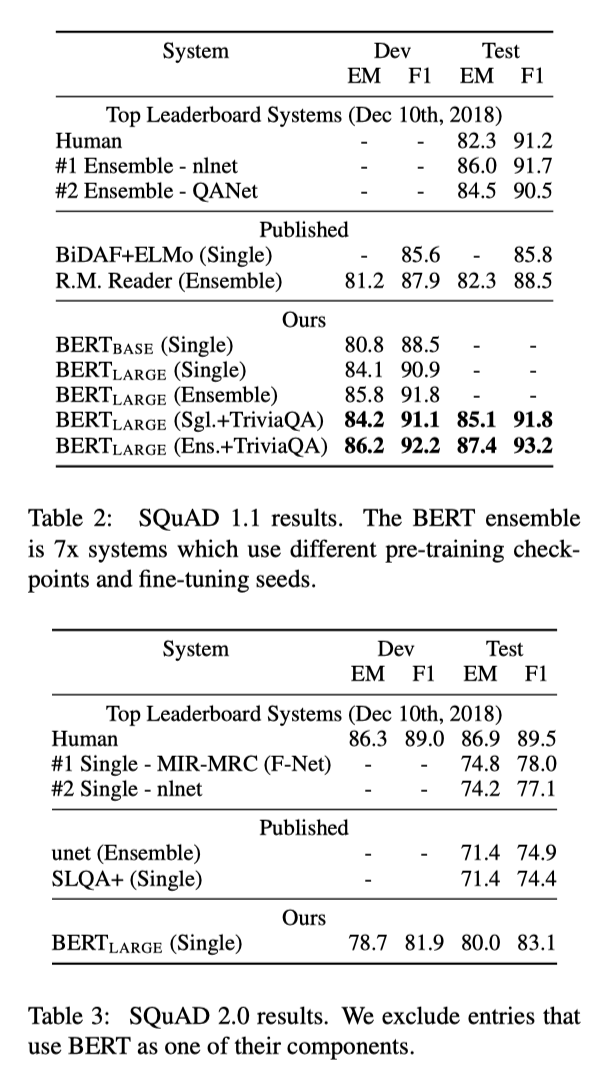 BERT ensemble模型和单模型提升F1 1.5 和 1.3 个点。
BERT ensemble模型和单模型提升F1 1.5 和 1.3 个点。 - SWAG
 BERT 相比 baseline 提升 27.1% , 相比 OpenAI GPT 提升 8.3%
BERT 相比 baseline 提升 27.1% , 相比 OpenAI GPT 提升 8.3% - 预训练的作用
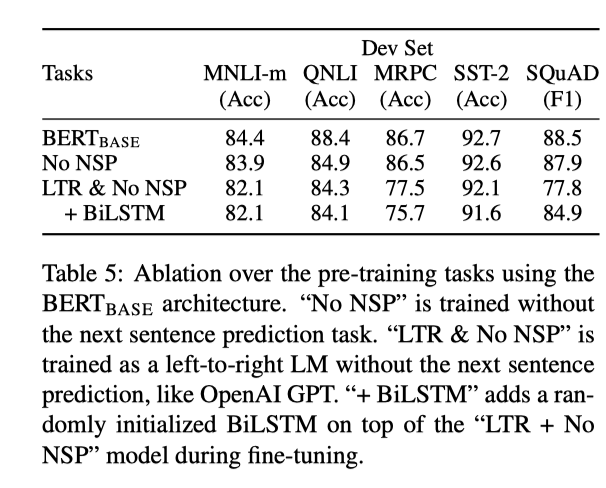 其中 “No NSP” 是去掉了 next sentence prediction 预训练阶段的模型,“LTR & NSP” 表示去掉 NSP 的同时使用从左到右的序列预测机制替代文中的 mask 机制, 可以看到去掉任何一个预训练都会带来明显掉点。
其中 “No NSP” 是去掉了 next sentence prediction 预训练阶段的模型,“LTR & NSP” 表示去掉 NSP 的同时使用从左到右的序列预测机制替代文中的 mask 机制, 可以看到去掉任何一个预训练都会带来明显掉点。 - 模型大小对性能的影响
 可以看到, 不断增大模型的尺寸能够获得持续的性能提升, 同时需要看到,使用预训练方法,即使在特定任务finetune数据集非常小时也能获得很好的性能。
可以看到, 不断增大模型的尺寸能够获得持续的性能提升, 同时需要看到,使用预训练方法,即使在特定任务finetune数据集非常小时也能获得很好的性能。