An Empirical Study of Training Self-Supervised Vision Transformers 链接到标题
* Authors: [[Xinlei Chen]], [[Saining Xie]], [[Kaiming He]]
- MoCo v1: [[@he2020]]
- MoCo v2: [[@chen2020]]
初读印象 链接到标题
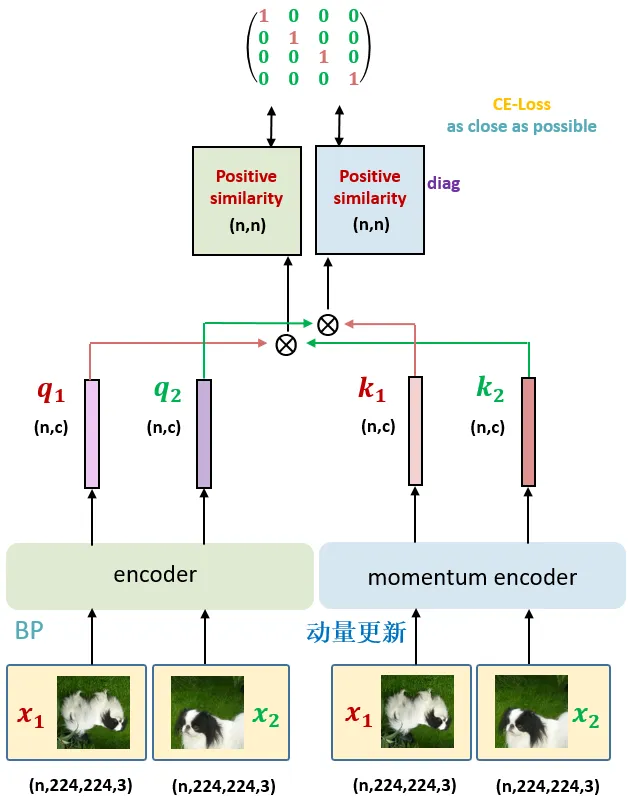
MoCo v3:1) 去掉 memory queue,2) 除了 backbone 和预测头 projection head 外,还类似于 BYOL 添加了 prediction head, 3) 如下图所示,两种 aug 图同时经过 $f_q$ 和 $f_Mk$ , 然后交叉做矩阵相似度计算 loss。 另外更换 backbone 为 ViT 时第一层 patch embeding 参数初始化后 freeze 解决 ViT 作为 backbone 时训练不稳定导致掉点的问题。