Big Self-Supervised Models are Strong Semi-Supervised Learners 链接到标题
* Authors: [[Ting Chen]], [[Simon Kornblith]], [[Kevin Swersky]], [[Mohammad Norouzi]], [[Geoffrey Hinton]]
初读印象 链接到标题
作者发现 SSL 任务中模型的大小很重要,使用更大更深的模型可以明显提高性能而不用担心过拟合。同时无标签借助蒸馏可以得到又小又好的小模型
Method 链接到标题
- 在使用无标签数据集做 Pre-train 的这一步中,模型的尺寸很重要,用 deep and wide 的模型可以帮助提升性能。
- 使用无标签数据集做 Pre-train 完以后,现在要拿着有标签的数据集 Fine-tune 了。之后再把这个 deep and wide 的模型 蒸馏成一个更小的网络。
Unsupervised Pre-train, Supervised Fine-tune,Distillation Using Unlabeled Data.
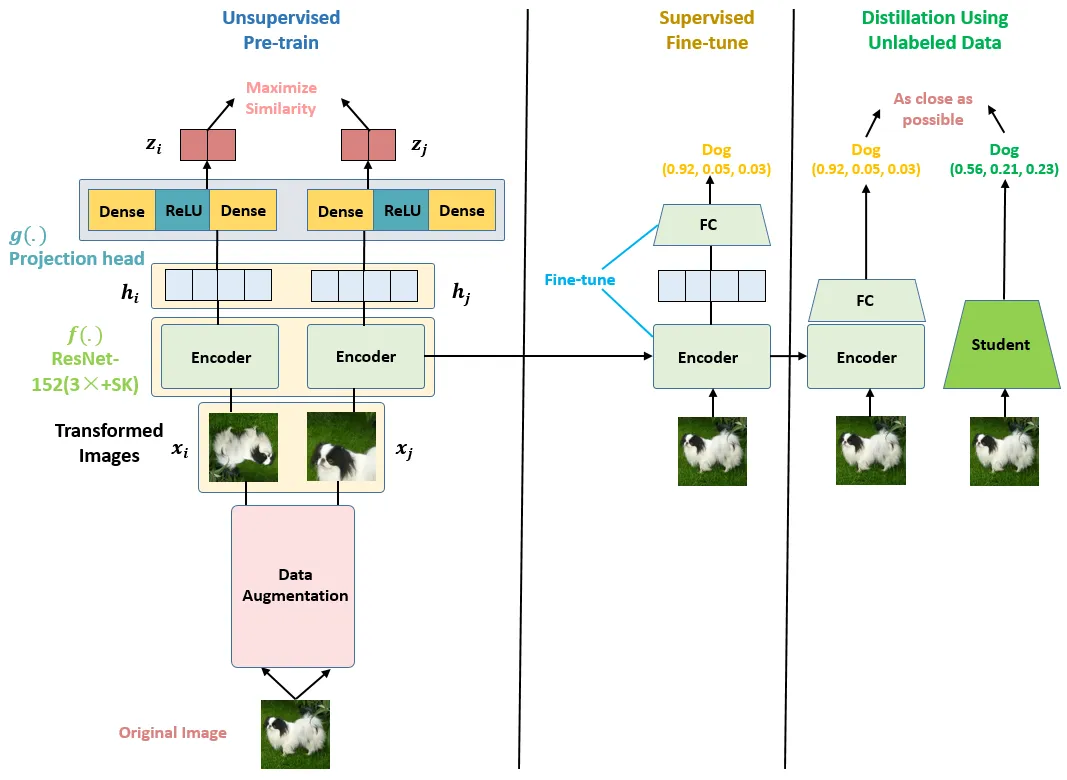
具体步骤分三步:
- 无标签数据预训练
- 有标签数据以 task-specific 方式 finetune
- 无标签数据以 task-specific 方式蒸馏得到更小的 Encoder
模型上的变化:
- Encoder 变深变宽:ResNet-50(4x) -> ResNet-152(3x) + selective kernels(SK)
- projection head 变深:从2层 fc 变成了 3 层
- 加入 MoCo 的内存机制
蒸馏损失函数:
$$\begin{aligned}\mathcal{L}^{\text{distill}}=-\sum_{\boldsymbol{x}_i\in\mathcal{D}}\left[\sum_y P^T(y|\boldsymbol{x}_i;\tau)\log P^S(y|\boldsymbol{x}_i;\tau)\right]\end{aligned}$$
其中 $P(y|\boldsymbol{x}_i)=\exp(f^{\text{task}}(\boldsymbol{x}i)[y]/\tau)/\sum{y’}\exp(f^{\text{task}}(\boldsymbol{x}_i)[y’]/\tau)\$ ,我们希望 Teacher 的概率和 Student 越接近越好
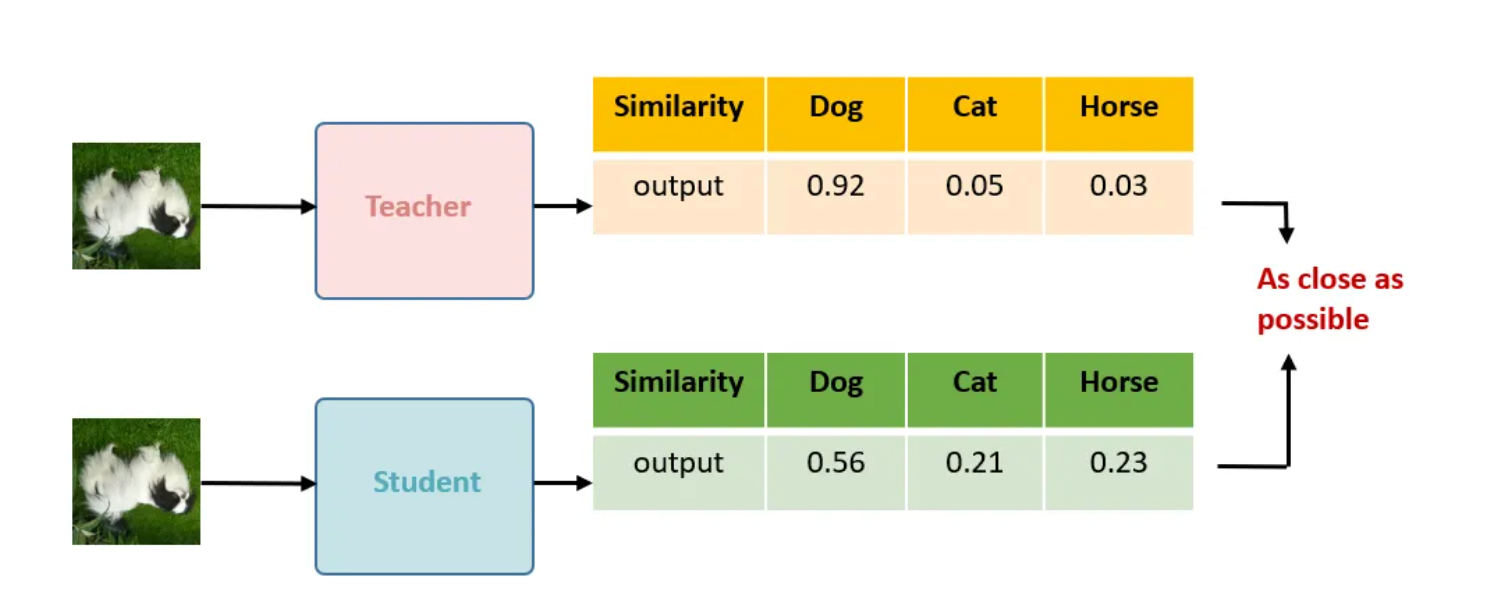
当然如果有部分标注数据,也是可以加入到蒸馏损失里面的
$$\mathcal{L}=-(1-\alpha)\sum\limits_{(\boldsymbol{x},y_i)\in\mathcal{D}^L}\left[\log P^S(y_i|\boldsymbol{x}i)\right]-\alpha\sum\limits{\boldsymbol{x},\in\mathcal{D}}\left[\sum_y P^T(y|\boldsymbol{x}_i;\tau)\log P^S(y|\boldsymbol{x}_i;\tau)\right]$$